Automattic, l'azienda dietro a WordPress e Tumblr, sta pianificando discussioni per monetizzare i contenuti degli utenti vendendo i loro dati a società di intelligenza artificiale, tra cui MidJourney e OpenAI. Questi dati dalle piattaforme di blogging Tumblr e WordPress.com saranno utilizzati per addestrare modelli di intelligenza artificiale.
Sebbene i dettagli della transazione siano ancora poco chiari, questa notizia ha suscitato preoccupazioni tra gli utenti riguardo all'eventuale utilizzo improprio dei loro contenuti privati sulle due piattaforme di blogging. Inoltre, 404 Media suggerisce che siano sorti conflitti interni all'interno di Automattic poiché i contenuti raccolti includono dati privati che non erano destinati a essere conservati all'interno dell'azienda.
In risposta alle reazioni negative, Automattic prevede di introdurre una nuova funzionalità che consentirà agli utenti di scegliere di non condividere i propri dati per l'addestramento dell'intelligenza artificiale. In un post sul blog, l'azienda ribadisce il suo impegno nel fornire agli utenti di Tumblr e WordPress un maggiore controllo sui propri contenuti. Si menziona il lancio di un'impostazione per "sconsigliare l'esplorazione da parte delle aziende di intelligenza artificiale", spiegando che le principali piattaforme di esplorazione AI sono bloccate per impostazione predefinita.
Il problema dell'utilizzo dei contenuti dei blog da parte delle aziende che sviluppano modelli AI non è limitato alle piattaforme gestite da Automattic. Sia OpenAI che Google utilizzano robot crawler per raccogliere informazioni da tutti i siti web per addestrare modelli di intelligenza artificiale. Il processo è simile alla raccolta di dati da parte dei motori di ricerca.
Come puoi bloccare OpenAI e Gemini (Bard) dal raccogliere dati dal tuo blog?
Se possiedi un blog o un sito web e non vuoi che i suoi dati vengano utilizzati per addestrare i modelli di intelligenza artificiale di OpenAI e Gemini, puoi bloccare l'accesso ai robot (crawlers) al contenuto. Questa restrizione può essere implementata tramite il file robots.txt.
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
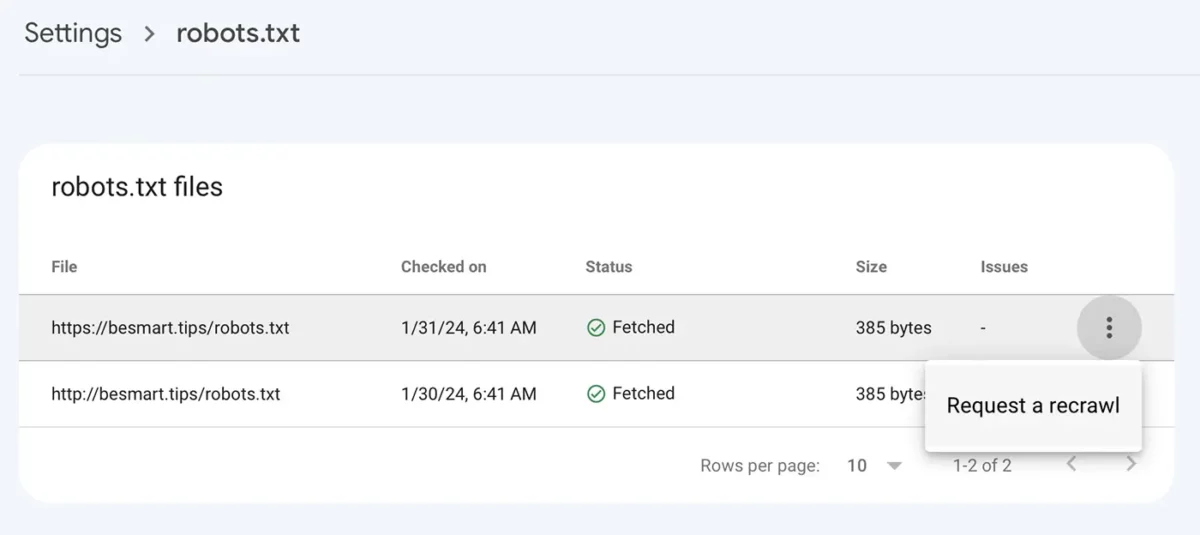
Disallow: /Dopo aver salvato il file robots.txt con le nuove righe, vai su Google Console a: Impostazioni > robots.txt > clicca sul menu con i tre punti, clicca su "Richiedi una nuova scansione".
Correlato: GPT-5 e il nuovo web crawler GPTBot sviluppato da OpenAI.
Per gli utenti di Tumblr e WordPress, l'accesso al recupero dei dati dai blog da parte di OpenAI o altre aziende che sviluppano intelligenza artificiale può essere bloccato tramite gli strumenti forniti da Automattic.