Il più delle volte, quando è necessario bloccare l'accesso SeekportBot o altri crawl bots con un sito web, i motivi sono semplici. Il web spider effettua troppi accessi in un breve lasso di tempo e richiede le risorse del web server, oppure proviene da un motore di ricerca in cui non si desidera che il proprio sito venga indicizzato.
È molto vantaggioso per un sito Web visitato da crawL'ho urtato. Questi web spider sono progettati per esplorare, elaborare e indicizzare il contenuto delle pagine web nei motori di ricerca. Google e Bing utilizzano tale crawL'ho urtato. Esistono però anche motori di ricerca che utilizzano robot per raccogliere dati dalle pagine web. Seekport è uno di questi motori di ricerca, che utilizza crawil SeekportBot ler per l'indicizzazione delle pagine web. Sfortunatamente, a volte lo utilizza eccessivamente e crea traffico non necessario.
Soddisfare
Cos'è SeekportBot?
SeekportBot è un web crawler sviluppato dalla società Seekport, che ha sede in Germania (ma utilizza IP di diversi paesi, inclusa la Finlandia). Questo bot viene utilizzato per eseguire la scansione e indicizzare i siti Web in modo che possano essere visualizzati nei risultati dei motori di ricerca. Seekport. Un motore di ricerca non funzionante, per quanto ne so. Almeno, non mi ha restituito alcun risultato per nessuna frase chiave.
SeekportBot usi user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"Come bloccare l'accesso a SeekportBot o altro crawHo cliccato su un sito web
Se sei giunto alla conclusione che questo web spider o un altro, non è necessario scansionare l'intero sito web e fare traffico inutile al server web, hai diversi metodi con cui puoi bloccarne l'accesso.
Firewall a livello di server web
Sono applicazioni firewall open-source che può essere installato sui sistemi operativi Linux e può essere configurato per bloccare il traffico in base a diversi criteri. Indirizzo IP, posizione, porte, protocolli o agente utente.
APF (Advanced Policy Firewall) è un tale software attraverso il quale è possibile bloccare i bot indesiderati, a livello di server.
Poiché SeekportBot e altri web spider utilizzano più blocchi di IP, la regola di blocco più efficace si basa su "user agent". Quindi, se vuoi bloccare l'accesso SeekportBot per mezzo di APF, tutto ciò che devi fare è connetterti al server web tramite SSHe aggiungi la regola del filtro nel file di configurazione.
1. Apri il file di configurazione con nano (o altro editore).
sudo nano /etc/apf/conf.apf2. Cerca la riga che inizia con "IG_TCP_CPORTS" e aggiungi l'agente utente che desideri bloccare alla fine di questa riga, seguito da una virgola. Ad esempio, se vuoi bloccare user agent "SeekportBot", la riga dovrebbe essere simile a questa:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. Salvare il file e riavviare il servizio APF.
sudo systemctl restart apf.serviceL'accesso a "SeekportBot" verrà bloccato.
Filtrazione web crawls con l'aiuto di Cloudflare – Blocca l'accesso di SeekportBot
Con l'aiuto di Cloudflare, mi sembra il metodo più sicuro e conveniente con cui limitare in vari modi l'accesso di alcuni bot a un sito web. Il metodo che ho usato anche nel caso SeekportBot per filtrare il traffico verso un negozio online.
Supponendo che tu abbia già aggiunto il sito Web a Cloudflare e che i servizi DNS siano attivati (ovvero, il traffico verso il sito Web passa attraverso Cloudflare), procedi nel seguente modo:
1. Apri il tuo account Clouflare e vai al sito Web per il quale desideri limitare l'accesso.
2. Vai a: Security → WAF e aggiungi una nuova regola. Create rule.
3. Scegli un nome per la nuova regola, Field: User Agent - Operator: Contains - Value: SeekportBot (o altro nome del bot) – Choose action: Block - Deploy.
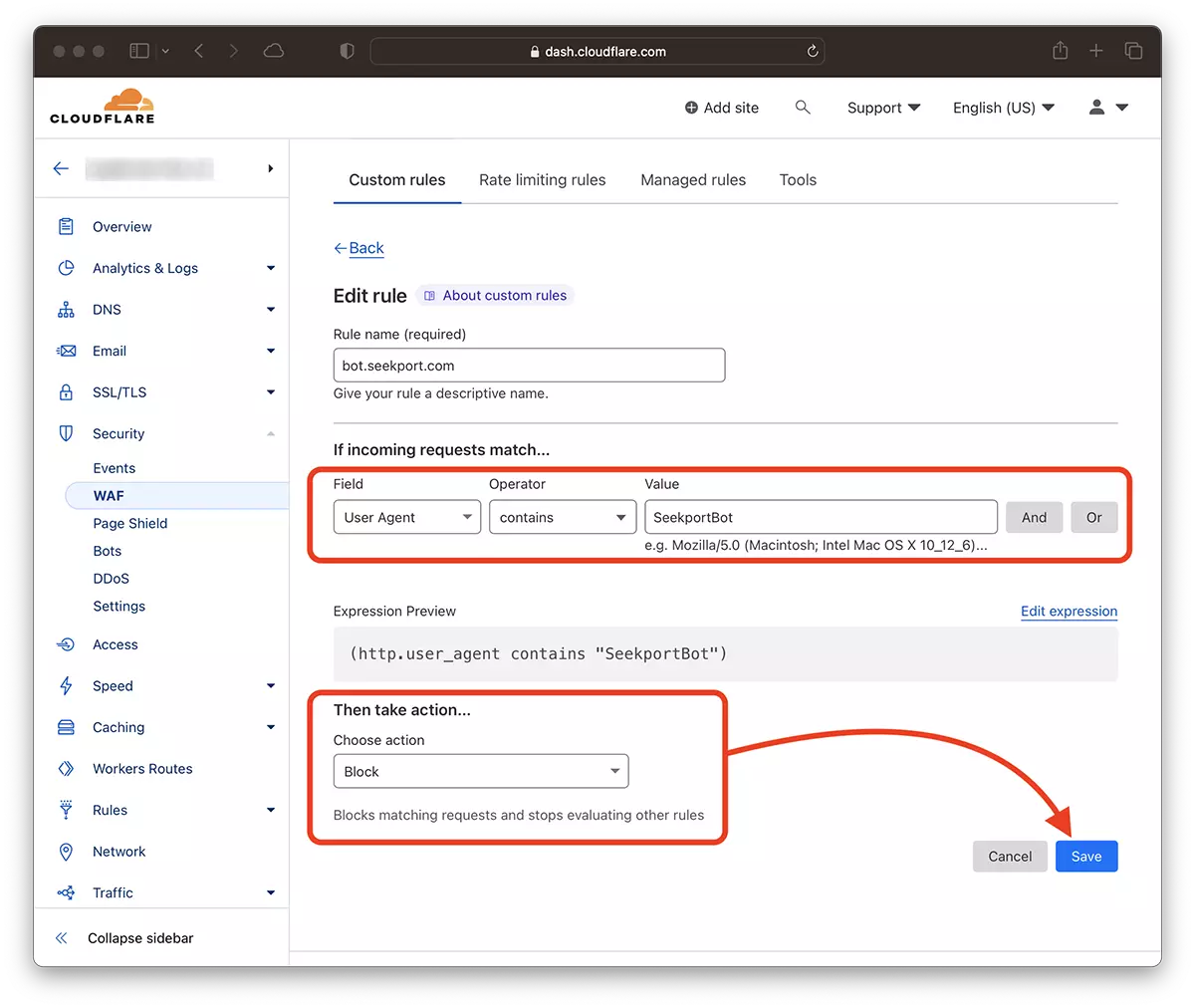
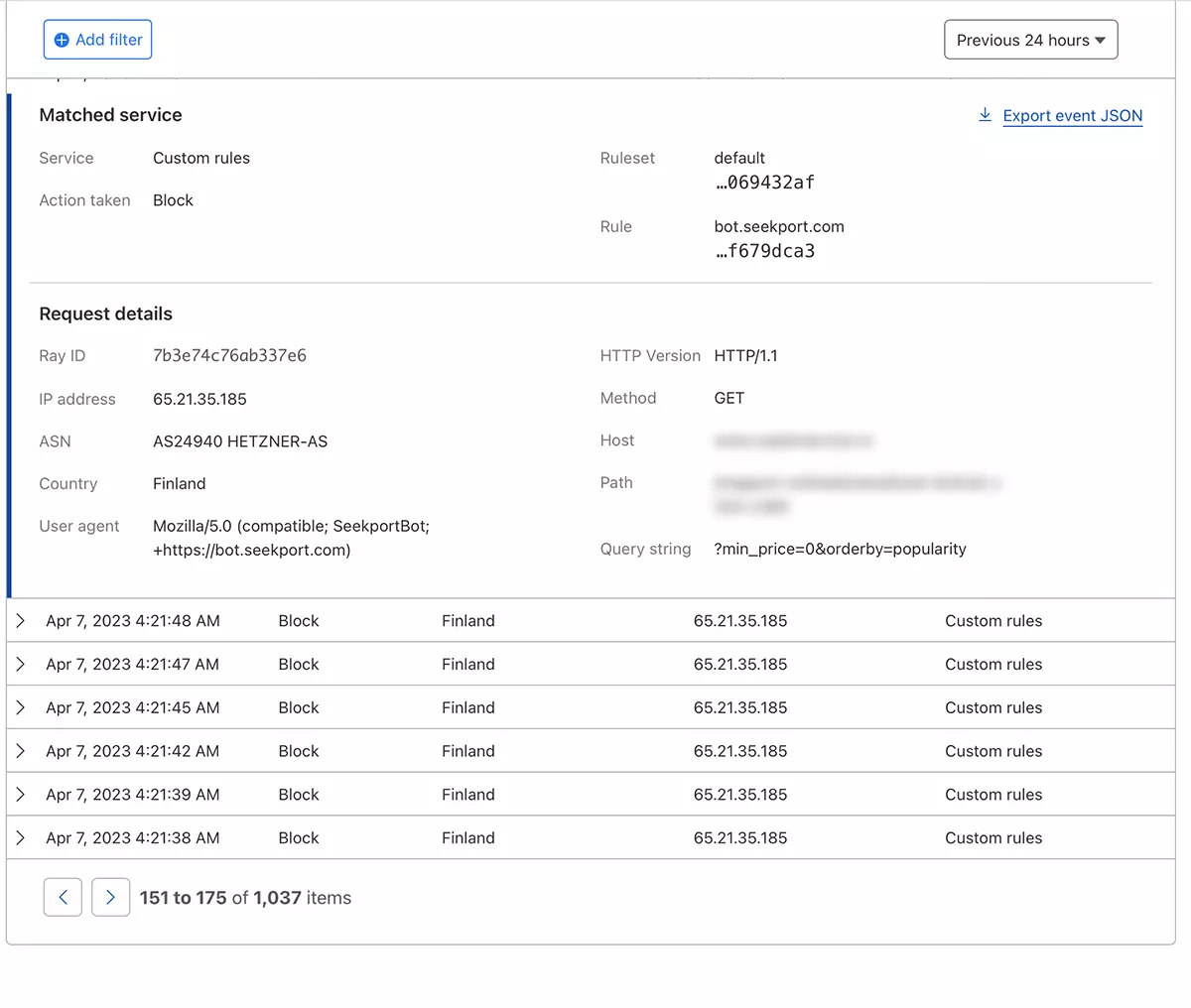
In pochi secondi, la nuova regola WAF (Web Application Firewall) inizia a fare effetto.
In teoria è possibile impostare la frequenza con cui un web spider accede a un sito robots.txt, ma... è solo in teoria.
User-agent: SeekportBot
Crawl-delay: 4Molti web crawlerii (eccetto Bing e Google) non seguono queste regole.
In conclusione, se identifichi un web crawl che accede eccessivamente al tuo sito, è meglio bloccare completamente il suo accesso. Certo, se questo bot non proviene da un motore di ricerca in cui sei interessato ad essere presente.